
Security Team Intelligence
Time is Money, Part 2: Vulnerability Analysis
- Jan 22, 2019
- Guest Author
This is part two in a six-part series. You can find the first in this series here, which lists the maturity levels we’ll refer to in this post.
Most organizations we encounter are at maturity level 2 or 3. At level 3, organizations have the financial and management support needed, but are still staring down a very long list of issues. Normally, more data results in better visibility… to a point. In this post, we’ll discuss some of the reasons this data is difficult to use and some of the techniques we use to clean it up.
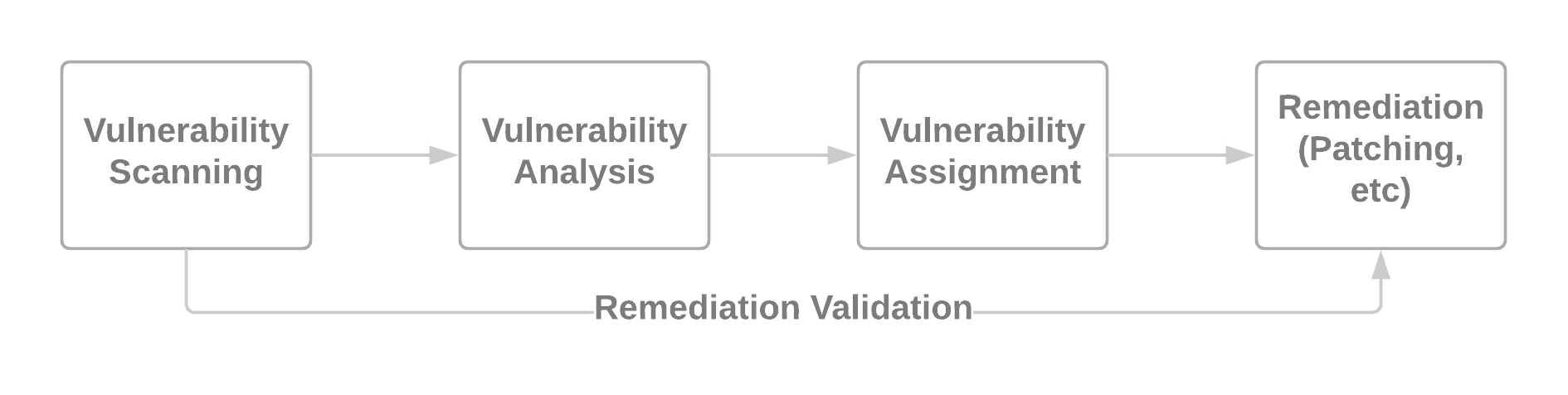
First, however, we’ll go over a simplified view of a typical enterprise vulnerability management cycle, as this process will be referenced throughout the rest of the Time is Money series.
Simplified Vulnerability Management Process
There is a lot more detail and complexity to this process, of course, but these are generally the major steps of the vulnerability management process, from discovery of an issue to fixing the issue and validating the fix works. As the title of this post suggests, we will focus on the second step in this cycle – vulnerability analysis.
For any organization scanning 2,000 assets or more, the data becomes incomprehensible. However, this data often isn’t any more complex than the results from a scan of 200 assets. We’re seeing mostly the same vulnerabilities, but multiplied by a factor of ten.
To understand this, we need to go into how most scanners report vulnerabilities. Let’s say we have an old version of Java on these 2,000 assets. Let’s also assume 80 critical Java vulnerabilities have been discovered since this version was released. A vulnerability scanner will count that as 160,000 critical vulnerabilities and will list each individual vulnerability in its user interface, or in any report we export.
The problem is, we don’t actually know Java is a big problem initially, we just see almost 200,000 critical vulnerabilities on the dashboard of the vulnerability scanner. The first thing we need to do is logically deduplicate this data. An improvement would be to list Java as vulnerable on 2,000 assets. That consolidates 160,000 line items down to 2,000 – a significant reduction. However, if we consider that the outcome is simply to update Java, rather than individually patching each of the 80 vulnerabilities on all 2,000 assets, we could further consolidate this to a single ‘task’: Upgrade Java on these 2,000 assets.
Of course, it’s not always as straightforward. Some of these assets may need an older version of Java, so some would be updated while others remain at the old version. We’ll need to somehow mitigate the risk of running a vulnerable version of Java on the latter systems. In some cases, we’ve seen organizations that realize they no longer need Java and simply remove it from 2,000 systems, eliminating 80% of their critical risk in one day.
This is just one example of deduplication. We also have opportunities to deduplicate across multiple scan results from the same, or different scanners, for example.
Even after deduplication, we often find there are still too many vulnerabilities to fix, even if we filter at the most critical level. In our previous Java example, we would still be left with thousands of critical vulnerabilities after deduplication. The next step is to take a look at what makes a vulnerability ‘critical’ in the first place.
The primary concern is the chance that a malicious actor may leverage vulnerabilities to cause harm to the organization.
“Isn’t there already a scoring system that service this purpose,” you might ask? CVSS is widely used to score vulnerabilities and is included in the scan results we previously mentioned. The trouble is that CVSS isn’t really intended to score risk, which makes it not very useful on its own. The CVSS score and the factors that contribute to the score are still useful, however, and are factored into NopSec’s more holistic risk score.
In addition to CVSS, there are many more factors to consider. First and foremost are false positives. Vulnerability scanners sometimes have to make guesses and sometimes those guesses are wrong. NopSec can automatically validate some vulnerabilities to determine if the report is a false positive, or if the issue really exists. E3 Engine is part of Unified VRM and can test vulnerabilities as a penetration tester would, to determine whether or not a finding is a false positive.
Next are threats. Threats allow attackers to use vulnerabilities against us. An exploit is a technique or piece of code that allows attackers to leverage a vulnerability to do something beneficial to the attacker. Exploits have a variety of outcomes. Some cause a service to crash (Denial of Service). Some give the attacker access to the victim computer (RCE, or remote code execution) and some give the attacker expanded access to a system (privesc, or privilege escalation).
Threats also fall into a few categories. NopSec receives ‘threat intelligence’ feeds from a variety of sources to address each of these categories. There are exploits that are publicly available but either aren’t functional or don’t seem to be in active use. There are exploits or malware that are currently in-use and are targeting specific vulnerabilities. Finally, there are vulnerabilities NopSec predicts will be targeted by the next big exploit or malware.
To summarize, there are threats we know exist, threats currently being used and threats that are likely to exist in the near future. NopSec uses threat intelligence and machine learning models to identify each of these categories.
The final factor is asset importance, which creates an opportunity for the business to have an impact on the risk score. An asset that is less or more important to the business can be scored accordingly. The end result will reflect this adjustment.
Ultimately, deduplication and prioritization are tasks that security staff traditionally do manually through Internet research and data analysis techniques that often involve spreadsheets. By automating this work, NopSec aims to create massive time savings for its customers, which will be quantified and discussed later in this series.
Next, we’ll begin discussing the process of fixing vulnerabilities and other issues. Stay tuned for Time is Money, Part 3: Vulnerability Assignment.
Every day I get tot talk to a lot of infosec professionals and business people regarding vulnerability management. They tell…
The other day I was thinking about the concept of “event correlation” embedded into various SIEM products. Security events can…
Some of you probably wondered where the NopSec crew and I ended up these days….already tired for blog writing? Not…

