
Threat and Exposure Research
Machine Learning in Cybersecurity Course – Part 1: Core Concepts and Examples
- Mar 25, 2019
- Shawn Evans
Spam detection, facial recognition, market segmentation, social network analysis, personalized product recommendations, self-driving cars – applications of machine learning (ML) are everywhere around us. Many security companies are adopting it as well, to solve security problems such as intrusion detection, malware analysis, and vulnerability prioritization. In fact, terms such as machine learning, artificial intelligence and deep learning get thrown around so much these days that you may be tempted to dismiss them as hype. In order to provide a framework for thinking about machine learning and security, in our last week’s webinar on Machine Learning in Cybersecurity, we covered the core concepts of machine learning, types of machine learning algorithms, the flowchart of a typical machine learning process, and went into details of three specific security problems that are being successfully tackled with machine learning – spam detection, intrusion detection, and vulnerability prioritization. Finally, we covered some common challenges encountered when designing machine learning systems, as well as adversarial machine learning in specific. In this blog post, we summarize the first part of that webinar, without going into the three specific applications and the challenges. We will cover those in Part 2 of this blog series, so stay tuned for next week’s post.
For more details, that entire webinar is now available on demand here. For even more details, and implementation examples in Python, we highly recommend Machine Learning & Security book by Clarence Chio and David Freeman – many of the examples we used in the webinar and in this post are discussed in more detail there.
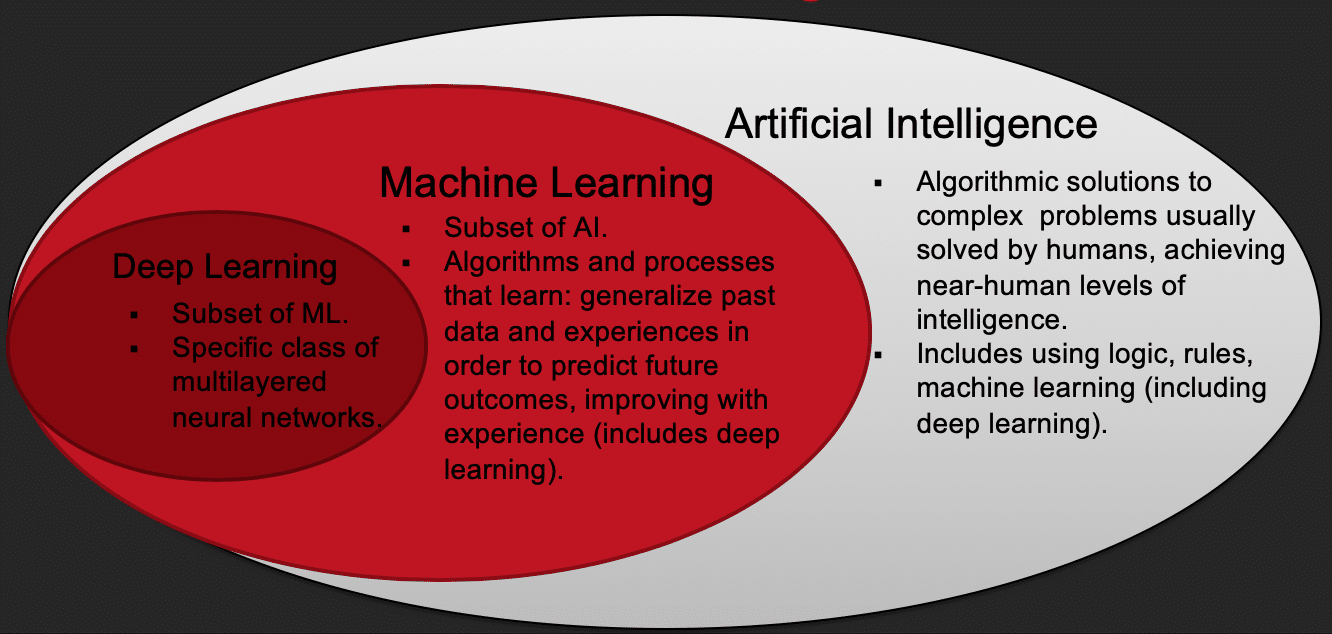
Artificial Intelligence (AI) is a loosely defined term that refers to algorithmic solutions to complex problems that are traditionally solved by humans. Sometimes there is an added requirement that these algorithms need to be able to achieve near-human-level intelligence in order to be considered AI. What is near-human-level intelligence is often left open for interpretation. AI includes using logic, rules, machine learning, etc. to solve complex problems.
Machine Learning (ML) is a subset and a core building block of AI. The formal definition, due to Tom M. Mitchell, defines machine learning algorithms as follows: “A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.” Basically, ML refers to algorithms that learn in the sense of being able to generalize past data and experiences in order to predict future outcomes, improving with experience.
Deep Learning is a strict subset of ML referring to a specific class of algorithms – multilayered neural networks.
There are two main types of ML algorithms: supervised and unsupervised.
Supervised learning refers to problems where you have labels or outcomes for past data and you want to predict labels for future data. There are two subtypes of supervised learning: classification, where the task is to predict discrete categories, and regression, where the task is to predict continuous numerical values.
On the other hand, in unsupervised learning you draw abstractions from unlabeled data and apply those abstractions to new data. A common example of unsupervised learning is clustering.
Examples:
Let’s say you manage a large online video rental platform with many subscribers. You may find all three types of algorithms useful to solve your problems. For example,
Two additional types of ML that are encountered less in the security domain are reinforcement learning and recommendation systems. In reinforcement learning an agent learns from rewards via a feedback loop with the environment, for example, a computer program learning to play a game (e.g., Google’s AlphaGo). Recommendation systems are used by platforms such as Netflix, Amazon, Spotify, and many others, to make personalized recommendations. They boil down to predicting preference or rating a user would give to an item. They can involve a mix of supervised and unsupervised techniques.
The process of going from a business problem to a predictive model usually involves the following steps:
Going from a business problem to a predictive model is usually an iterative process that may involve experimentation at every step – if, after step 7, we are not satisfied with the performance, we may want to tune the model parameters further, add new features, or pick a different algorithm. At its core, an ML algorithm takes a training dataset and outputs a model. The model is an algorithm that takes in new data points in the same form as the training data and outputs a prediction.
Let’s imagine you are in charge of a computer security at your company. Here are some questions that you may encounter that could be framed as:
Machine learning applications in cybersecurity come in two main forms: pattern detection and anomaly detection.
In pattern detection, we try to discover explicit or latent characteristics hidden in the data, and use them to teach an algorithm to recognize other forms of the data that exhibit the same set of characteristics. Patterns are inferred from the training data.
In anomaly detection, instead of learning specific patterns that exist in the data, the goal is to establish a notion of normality that describes most of a given dataset. Deviations from this will be detected as anomalies (outliers). There can be an infinite number of anomalies.
Since the two applications are often conflated with each other, it helps to consider specific examples. For example, if you are looking for fraudulent credit card transactions, it might make sense to use a supervised learning model (pattern detection) if you have a large number of both legitimate and fraudulent transactions with which to train the model. The assumption is that all fraudulent transactions have some characteristics in common and that future fraudulent transactions will look similar to the ones we have already seen. In other scenarios, it can be difficult to find a representative pool of positive examples that is sufficient for the algorithm to get a sense of what positive events are like – for example, in intrusion detection, breaches can be caused by zero-day attacks or newly released vulnerabilities, with no previously known signature of attack. This is where anomaly detection is a better approach.
For a detailed description of three specific applications of ML in cybersecurity – spam detection, intrusion detection, and (our favorite) vulnerability prioritization, as well as an overview of challenges encountered when designing ML systems, stay tuned for next week’s Part 2 of this blog series, or watch the on demand webinar.
Machine Learning & Security by Clarence Chio & David Freedman
Every day I get tot talk to a lot of infosec professionals and business people regarding vulnerability management. They tell…
The other day I was thinking about the concept of “event correlation” embedded into various SIEM products. Security events can…
Some of you probably wondered where the NopSec crew and I ended up these days….already tired for blog writing? Not…

