
Product Announcements
Feature Update: NopSec Risk Scoring Algorithm Improvements
- Jul 05, 2022
- Michelangelo Sidagni
NopSec is announcing the first in a series of updates to our Risk Scoring Machine Learning Model aimed at improving our ability to recognize Common Vulnerabilities and Exposures (CVEs) that pose the greatest threat to our client’s security posture. This update has two significant changes:
These updates significantly improve our ability to find threat and threat-like CVEs while reducing the number of false positives.
Patching vulnerabilities can be a large task. Within a household alone, one might have a dozen different devices with their own vulnerabilities and update cycles. Keeping everything up-to-date, even on that rarely used desktop in the corner, takes concerted effort.
For an enterprise running a mix of commercial, open-source and proprietary code bases, vulnerability management can balloon to hundreds of thousands, and even to millions, of required actions. At NopSec, we help our clients make better informed decisions about which vulnerabilities to tackle first through our CVE Risk Scoring algorithm.
NopSec’s risk score algorithm is used to address the inadequacies of the Common Vulnerability Scoring System (CVSS) scores given to every CVE. While CVSS scores provide a first cut to prioritization, they are not scored based on the ability to exploit the vulnerability or by the usage of a vulnerability by threat actors. Of the 160,000+ documented CVEs in the National Vulnerability Database, only 21.8% have known exploits and an even smaller fraction, 1.5%, are associated with malware or exploit kits.
Figure 1 shows the CVSS Score distribution for all CVEs. 32% of CVEs are given a High Severity (score 7-10) yielding over 50,000 High Severity Vulnerabilities. Multiplied by the number of systems in an enterprise environment, this can lead to an unmanageable number of vulnerabilities for an IT team to deal with. If we focus on just those CVEs associated with malware or exploit kits (Figure 2), we find that 27% of these CVEs have a CVSS base score < 7 (medium or low severity). A CVSS based prioritization will miss a significant fraction of actual threats.
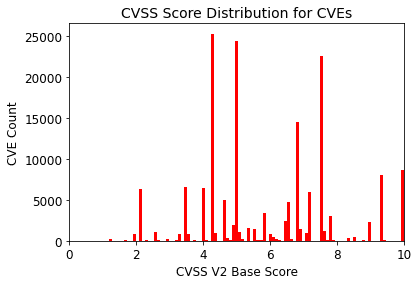
Figure 1. CVSS score distribution for all CVEs
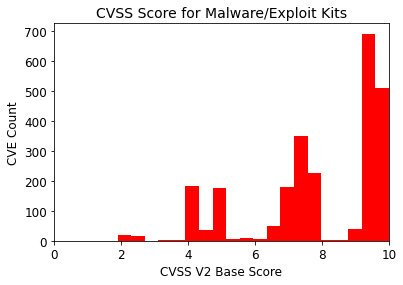
Figure 2. CVSS score distribution for threat CVEs
NopSec’s approach to CVE prioritization is to calculate a vulnerability risk score which is roughly the probability that a particular CVE will be used in targeted attacks in the wild or that there are highly weaponized exploit kits and malware making use of it. We do this by using a classification algorithm that uses threat intelligence, CVE properties (such as CVSS score), and social media mentions to distinguish between actual threats (those used in malware and targeted attacks) and non-threat CVEs. Each CVE is scored against the resulting model to provide a NopSec Risk Score which is then used within UVRM for vulnerability prioritization.
But creating the model is only part of the process. To remain vigilant, NopSec also monitors the accuracy of the model and the fidelity of the data used within the classification algorithm. Our risk score update includes a new feature and revised threat identifications as well as a retraining of the algorithm to provide more accurate threat identifications and better vulnerability prioritizations to our clients. This is the first in a series of changes that will be made to the risk score model to improve the data quality and model accuracy.
While there are a number of algorithmic methods by which to perform a classification, the most important part is the choice of data used in training and testing. Figure 3 provides an example of the impact of the classification choice on a model. The figures are a simplistic representation of a classification between blue triangles and red circles based on 2 features. By a simple change of one point from blue triangle (left) to red circle (right), we see that the best fit model changes substantially. Likewise, Figure 4 illustrates the importance of feature selection. On the left, we see that Feature 1 alone provides a reasonable, if not perfect, means of distinguishing the two classes while Feature 2 (right) has little to no power on its own to provide classification. Only in combination with Feature 1 is Feature 2 useful within a classification algorithm.
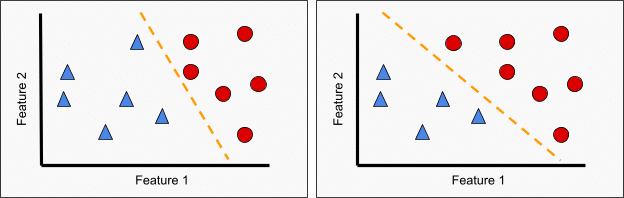
Figure 3. Impact of classification change
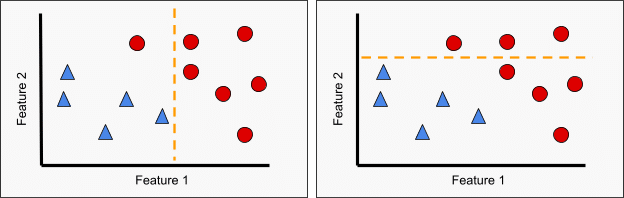
Figure 4. Impact of feature choice on classification
The first major change is a change to the threat identification. Based on our expert review of threat data, we found that one of our sources for threat identification included a large number of false positives. These CVEs may have had exploits, but they were not seen in the wild. We replaced that source with a new source that includes Sandbox detection of threats from suspicious files. This new source provides us with more confidence that our threats are out in the wild rather than a vague possibility that a vulnerability could be exploited.
The second major change is the addition of a new feature to provide time variability within the risk score model. On inspection, the accuracy of the old model in picking out threats was drifting over time with significantly decreased performance for more recent vulnerabilities. To understand the drift, we performed a time dependent analysis (i.e. determining the best-fit model in different time periods). From this, it was clear that feature importance significantly changed between the time periods indicating that the model parameters were changing over time. This is likely due to a combination of changing technologies (e.g. increased availability of open-source software, increased cloud computing usage) and changing priorities and techniques for threat actors (e.g. the rise of ransomware and crypto-mining malware). In order to account for these changes, we have added a new feature that allows the model to account for variations in feature importance over time and improves our ability to correctly identify threats both overall and in the most recent data.
These modifications to the NopSec risk score model enable us to better discriminate between threats and non-threats, reducing the number of false positive identifications and improving the true positive threat IDs. This provides our clients with more targeted information on the risk of a vulnerability and better prioritization.
Every day I get tot talk to a lot of infosec professionals and business people regarding vulnerability management. They tell…
The other day I was thinking about the concept of “event correlation” embedded into various SIEM products. Security events can…
Some of you probably wondered where the NopSec crew and I ended up these days….already tired for blog writing? Not…

