
Security Team Intelligence
Docker-based OpenVAS Scanning Cluster to Improve Scope Scalability
- Dec 01, 2015
- Michelangelo Sidagni
OpenVAS (Open Vulnerability Assessment Scanner) – is an open source security vulnerability scanner and manager. It is an open source fork of the commercial vulnerability scanner Nessus and it provides several options to manage distributed, remote, local scans and add several other specialized vulnerability scanners to the mix.
Since OpenVAS 8 was released with improved Master-Slave support for better distributed and load-balanced scanning, NopSec decided to build a proof of concept security vulnerability scanning cluster. Our goal was to use this to explore how we can reduce our scanning infrastructure footprint while increasing our ability to roll out new versions of the scanner without delays. We have also explored Docker within our production, development and testing systems and workflows. Docker containers wrap up a piece of software in a complete filesystem that contains everything it needs to run: code, runtime, system tools, system libraries – anything you can install on a server. This guarantees that it will always run the same way, regardless of the environment it is running in. So with all of this in mind we decided to build OpenVAS master and slave instances within docker containers, for the purpose of linking the scanning power to the number of hosts to be scanned.
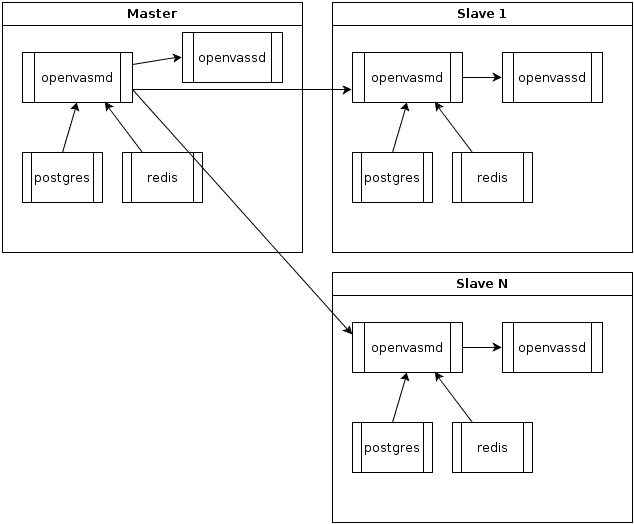
Below is an overview of an openvas / docker scanning cluster layout. Each docker container has a process of openvas manager and scanner running, along with PostgreSQL and Redis to support the openvas manager.
The Dockerfile and supporting scripts to build a openvas docket container are located in the following repository: https://github.com/wcollani/openvas-8-docker
The majority of our infrastructure currently uses Ubuntu. Docker presents the opportunity to use Debian without issues from a production standpoint while being able to stick to the same base that is the target development environment for OpenVAS.
Each Dockerfile installs all of the needed dependencies required to build the various packages for OpenVAS scanner. Each package is then built and installed. Redis and PostgreSQL are setup so that OpenVAS could store the knowledge base and save results and plugins.
The setup.sh script is used to configure the tasks table that is then used by the various OpenVAS components and sync scripts. So, every time OpenVAS needs to be re-synced we can just build a new version of our containers which can then be pushed into production.
The startup.sh script gets the container ready to run by ensuring each process is started and usable, then finally tails all of the OpenVAS logs so we can inspect any messages at run time.
This workflow was used during our testing phase. The added use of OpenVAS GUI frontend web app allows easier visualization and debugging of openvas, we would obviously not being using this in a production scenario.
1. Start the Master with explicit port mappings for ease of use. 9390 is open for the OpenVAS manager and 443 is open for the OpenVAS GUI web frontend
# cd master-manager
# docker build -t openvas-manager .
# docker run -d -p 9390:9390 -p 443:443 openvas-manager
2. Start the slave. No need for explicit port mapping for the openvas manager since many slaves were brought up and down during testing. A quick docker ps or inspect will tell you what port was chosen.
# cd slave-scanner
# docker build -t slave-scanner .
# docker run -d -p 9390 slave-scanner
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
05bca6ddc558 openvas-manager “/bin/bash /openvas/s” About an hour ago Up About an hour 0.0.0.0:443->443/tcp, 0.0.0.0:9390->9390/tcp, 9391-9392/tcp condescending_kilby
2e952b9c3b2b slave-scanner “/bin/bash /openvas/s” About an hour ago Up About an hour 443/tcp, 9391-9392/tcp, 0.0.0.0:32768->9390/tcp compassionate_blackwell
At this point in testing, the easiest way to control the master and slave is to use OpenVAS web-based GUI. But omp-cli commands would be just as easy.
Now that we have master and slave, the overview for our basic cluster logic is as follows.
number_of_IPs_per_slave = X
number_of_IPs_to_scan = Y
If number_of_IPs_to_scan > number_of_IPs_per_slave:
There are 3 major issues that remain before we can move this cluster into production.
Every day I get tot talk to a lot of infosec professionals and business people regarding vulnerability management. They tell…
The other day I was thinking about the concept of “event correlation” embedded into various SIEM products. Security events can…
Some of you probably wondered where the NopSec crew and I ended up these days….already tired for blog writing? Not…

