
Product Announcements
A little Machine Learning “Magic”…
- Apr 29, 2015
- Michelangelo Sidagni
This blog post is the first of a series documenting the journey into Machine Learning Algorithms NopSec is undertaking as part of Unified VRM data analytics capabilities.
In our last sprint, as part of Unified VRM, we started using Machine Learning – https://en.wikipedia.org/wiki/Machine_learning – to spot trends in past clients vulnerability data in order to abstract areas of the security program that need improvement in the future.
We selected two machine learning algorithms to express and summarize vulnerabilities areas:
The “Bag of Words” Machine Learning Algorithms – https://en.wikipedia.org/wiki/Bag-of-words_model – is a simplifying representation used in natural language processing and information retrieval (IR). In this model, a text (such as a sentence or a document) is represented as the bag (multiset) of its words, disregarding grammar and even word order but keeping multiplicity.
The bag-of-words model is commonly used in methods of document classification, where the (frequency of) occurrence of each word is used as a feature for training a classifier.
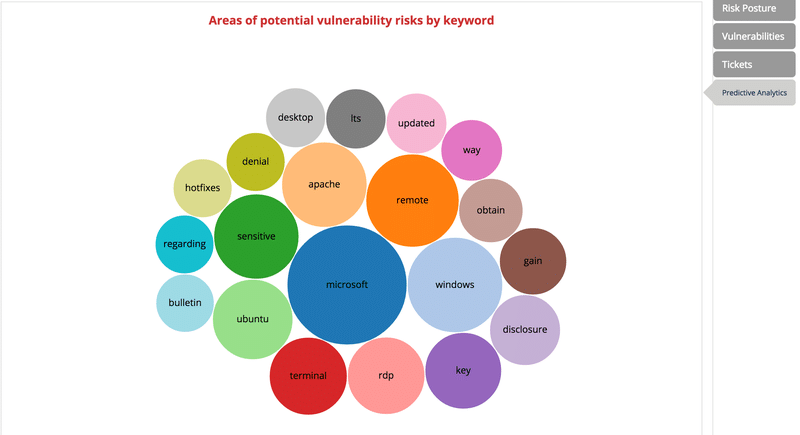
In conjunction with a natural language processing, we analyze past vulnerabilities title and description to look for recurring words that are indicative of vulnerability recurrence and area of in exploitability interest. Obviously we remove grammar and recurring English words and keep words that are common in vulnerability descriptive language. Using a “bubble” chart, we represent the most important words with biggest bubbles, thus indicating those areas / keywords are important for understanding the general exposure the specific organization is facing in terms of vulnerabilities areas – most likely by operating system and attack vectors.

The other machine learning algorithm we decided to use is the so called “Recommender“. Recommender systems have become extremely common in recent years, and are applied in a variety of applications. The most popular ones are probably movies, music, news, books, research articles, search queries, social tags, and products in general. This algorithm involves selecting a number of attributes that describe or influence the outcome of the phenomenon being studied, in our case vulnerabilities. The “recommender” system would return a number of recommendations based on the selected attributes chosen. In our specific case however returning recommendations based on past vulnerabilities would not make sense because it is known that a vulnerability is a software status. It is either there or not there, it cannot be recommended.
In order to overcome this algorithm limitation, we took the recommended vulnerabilities and identified their affected operating system / applications via CPE / CVE correlation and the related attack vector through CWE / CVE correlation. This way we were able to recommend Software Vendors / Applications that might be vulnerable in the future based on past experience as well as Attack Vectors that might be used by a motivated attacker based on past vulnerabilities found in the customers’ systems.
We then represented the riskiest vendors and attack vectors to be encountered in the future through a matrix scattered chart.
These two algorithms are the first two studied and selected. We will continue researching and exploring algorithms to describe the risk statuses of the organizations we serve.
Every day I get tot talk to a lot of infosec professionals and business people regarding vulnerability management. They tell…
The other day I was thinking about the concept of “event correlation” embedded into various SIEM products. Security events can…
Some of you probably wondered where the NopSec crew and I ended up these days….already tired for blog writing? Not…

