
Threat and Exposure Research
Machine Learning in Cybersecurity Course – Part 2: Specific Applications and Challenges
- Apr 08, 2019
- Shawn Evans
Spam detection, facial recognition, market segmentation, social network analysis, personalized product recommendations, self-driving cars – applications of machine learning (ML) are everywhere around us. Many security companies are adopting it as well, to solve security problems such as intrusion detection, malware analysis, and vulnerability prioritization. In fact, terms such as machine learning, artificial intelligence and deep learning get thrown around so much these days that you may be tempted to dismiss them as hype. In order to provide a framework for thinking about machine learning and security, in our recent webinar on Machine Learning in Cybersecurity, we covered the core concepts of machine learning, types of machine learning algorithms, the flowchart of a typical machine learning process, and went into the details of three specific security problems that are being successfully tackled with machine learning – spam detection, intrusion detection, and vulnerability prioritization. Finally, we covered some common challenges encountered when designing machine learning systems, as well as adversarial machine learning in specific.
In our last week’s blog post, we outlined the first part of that webinar, without going into the three specific applications and the challenges. In this post, we complete the story by summarizing the remaining topics covered in the webinar – the three specific applications of ML to security problems and the challenges. For each of the three specific problems, we will describe the problem and the motivation behind it, possible ML approaches, and what the results have been so far. For more details, the webinar is available on demand here. For even more details, and implementation examples in Python, we highly recommend Machine Learning & Security book by Clarence Chio and David Freeman – many of the examples we used in the webinar and in these posts are discussed in more detail there.
Spam detection is one of the oldest problems in security. Spam is defined as unsolicited bulk messaging, usually for the purpose of advertising or selling. It usually refers to email, even though it can similarly affect other ways of messaging. Even though it need not be malicious in nature, spam could include phishing or malware spreading. It is often dishonest, unethical, and fraudulent, and promotes products that offer little or no value. It is therefore important to differentiate legitimate messages from spam.
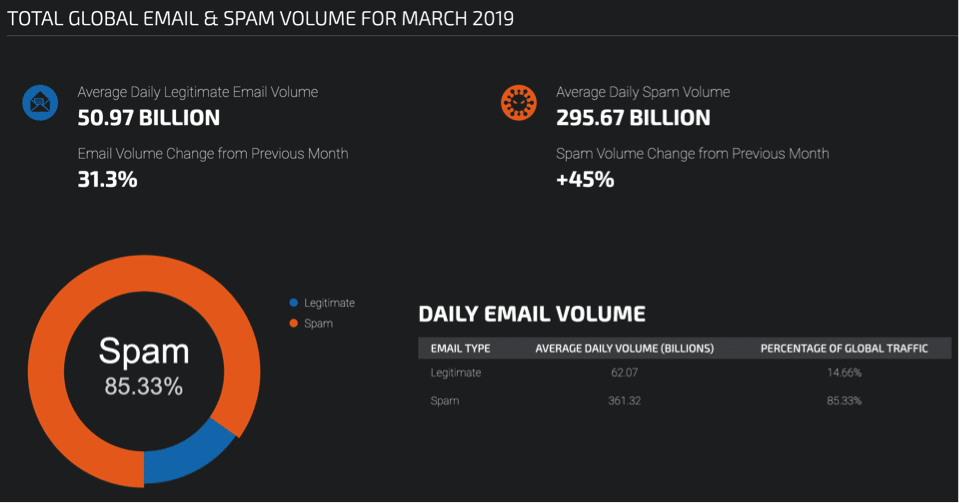
How big is the problem? Based on the most recent data from Talos Intelligence Group, about 85% of daily email volume can be attributed to spam!
Source: https://www.talosintelligence.com/reputation_center/email_rep.
Why aren’t we seeing more spam in our inboxes? We do not see as much spam as the numbers coming from Talos would imply, because the spam detection problem has been successfully tackled with machine learning and nowadays most of these emails never make it all the way to our inboxes!
If we were tasked with the problem of identifying spam, we could start with simple filtering of keywords. For example, we could tag all messages that contain the expression ‘make money’ as spam. This would likely catch some spam messages, but it would not get us very far. We would need to add keywords to identify different types of spam, and as the attack tactics used by spammers are likely to evolve over time, it would be difficult to keep up. Even more concerning is that we’d likely end up with many false positives – messages that are not spam but get labeled as spam due to some of these keywords being mentioned. A much more promising approach is to use supervised machine learning to classify emails as spam or non-spam based on a large collection of labeled spam and non-spam messages by using features derived from both the email content itself (message text, subject, links and images included, etc.) and the metadata (information about the source, time the message is sent, etc.). This approach has been so successful that Google claimed to be able to detect 99.9% of spam way back in 2015. Today, your Gmail inbox is likely almost entirely spam-free and a legitimate message will rarely get classified as spam. These are performance levels that are not achievable via simple filters and rules. One of the main advantages of ML is that ML algorithms have the capability to utilize large number of features and automatically adapt over time.
It should come as no surprise that breaches can be very costly to recover from, but what may be surprising is that 68% of data breaches stay undetected for months, according to the 2018 Verizon Data Breach Investigations Report (DBIR). Intrusion detection systems (IDS) are one way to stay a step ahead of potential attackers. An intrusion detection system monitors the network traffic looking for suspicious activity, which could represent an attack or unauthorized access. Intrusion detection systems have been around since 1986, but as those data breach detection timelines would suggest, the problem is far from solved.
How would we approach this problem starting from the basics? Let’s say there is a database we particularly care about. We may decide to monitor the number of requests to this database and set a threshold to raise alerts – for example, define an upper limit to the number of queries to this database in some time period. We immediately encounter issues such as:
Some improvements to this static threshold-based detection could include using a dynamic moving average (or median) number of requests for the number of allowed queries, grouping users by roles, setting different thresholds or a combination of thresholds in different scenarios, etc.
Just like with this basic thresholding example, simplest IDS work based on defined signatures. Signatures are distinctive characteristics present in exploits of known vulnerabilities. As such, signature-based IDS are designed to detect known attacks but cannot identify previously unseen threats. Some IDS incorporate rules (expert systems) to identify attacks that are similar to previously encountered attacks. In fact, just as we could start with simple filtering of words in the problem of spam detection, using thresholds, heuristics and simple statistics can be a reliable way of detecting intrusions for known attacks or attacks that follow the same pattern as the previously encountered ones. New signatures must be created when new attacks are discovered and they must be imported to the system immediately. As such, these systems are not resistant to true zero-day attacks. However, a major improvement can be made by using a hybrid approach where the benefits of combined signature and rule-based detection are further aided by ML, this time in form of anomaly detection.
As we discussed in last week’s post, anomaly detection aims to establish what the vast majority of data look like, and to identify any deviations from normal. An example method to detect anomalies would be time-series forecasting. For example, by looking at CPU utilization or number of requests over time, we may notice that these time series are linearly dependent on their own previous values and have observable trends, and methods like ARIMA (autoregressive integrated moving average) are likely to provide a good prediction of what future time-series should look like given what they looked like in the past. This prediction will come with a confidence interval, and anything outside of that confidence interval may then be labeled as an anomaly. More complex time-series data may require neural network applications to get reliable predictions. Forecasting methods work well when anomalies are contained in test data only, but not in the training data (novelty detection) and when the time series follow observable trends.
Anomaly-based IDS is able to detect zero-day attacks, but could also have a high false alarm rate dependent on the threshold for anomaly detection, which in turn may be very application-specific.
At the moment of writing of this post (April 3rd, 2019), there have been ≈ 110 000 vulnerabilities published (and assigned CVSS scores) in the National Vulnerability Database, with ≈ 34 000 of those having been disclosed since the beginning of 2017. The vulnerability spike could be explained by many factors such as an ever-expanding attack surface, companies being better at engaging with the security community, proliferation of many private and public bug bounty programs, etc. Given this sea of vulnerabilities documented in the NVD, a full scan of all of a company’s assets may reveal hundreds of thousands, or even millions of vulnerabilities to address, as the numbers get scale by the number of assets and ports scanned.
Since remediation requires considerable efforts, prioritizing what to fix first becomes very important. The traditional way of using CVSS score to do this has been shown to be inadequate. CVSS base score is a measure of theoretical severity of a vulnerability (ease of exploitability and potential impact if exploited), but not a measure of the actual risk as it does not consider either the temporal evolution of the vulnerability (such as incorporation into malware) or the user context (asset value). In our 2018 State of Vulnerability Risk Management Report, we showed that prioritizing based on high or critical CVSS is neither an efficient nor a safe strategy due to two major issues:
To estimate the real risk, we need to compute the probability that a vulnerability will be associated with a threat – incorporated into malware (ransomware, remote access trojans, etc.) and exploit kits, or used in targeted attacks.
We have also found that factors beyond the CVSS base score, such as vulnerability age, type and number of vendors and product affected, language used in vulnerability descriptions, existence of exploits based on multiple threat feeds, and social media mentions, may be important in distinguishing those vulnerabilities that do not get associated with threats (and hence pose lower risk) from those that do.
Vulnerability prioritization can then be framed as a supervised classification problem: given historical vulnerabilities with some characteristics (such as the factors mentioned above) and labels (“not associated with a threat” vs. “associated with a threat”) we would like to know the likelihood that a newly disclosed vulnerability will be associated with a threat. We can then train a supervised classification algorithm to predict threat association. We have found that the algorithm obtained this way performs way better (relative to CVSS) in both reducing the number of vulnerabilities to focus on by having fewer false positives, where vulnerabilities that will never get associated with a threat get labeled as such (issue 1 above), and fewer false negatives, where vulnerabilities get omitted from prioritization efforts but do end up getting weaponized (issue 2 above).
There are many challenges encountered when designing machine learning systems, some of which are:
Machine learning tools and advances are available not only to those looking to protect us from spam, intrusions, and exploits, but also to those on the opposite side of this battle – researchers have been warning us for a while now that attackers have begun to adopt machine learning techniques themselves. Some examples that have been seen “in the wild” include hacking tools making advantage of machine vision to defeat Captchas and spammers applying polymorphism techniques (changing the form without changing the meaning) to circumvent detection. Researchers have even shown that it is possible to use ML to craft more successful phishing messages based on personal data available on social media.
Another major concern is model poisoning – intentional introduction of misleading data. If attackers can figure out how an algorithm is set up, or where it draws its training data from, they may be able to figure out ways to introduce misleading data. ML systems need to be designed with security in mind!
Machine Learning & Security by Clarence Chio & David Freedman
State of Vulnerability 2018 Report
Every day I get tot talk to a lot of infosec professionals and business people regarding vulnerability management. They tell…
The other day I was thinking about the concept of “event correlation” embedded into various SIEM products. Security events can…
Some of you probably wondered where the NopSec crew and I ended up these days….already tired for blog writing? Not…

